Incident Management Tools and Workflows: Putting It All Together

Categories
Incident Management
Choosing the right incident management tools is an important step to effectively dealing with incidents. We try not to reinvent the wheel when we choose our tools. In my first blog, we reviewed five fundamentals of incident management, and one of them was ease. We also integrate the tools our incident team members use daily, with xMatters as the hub. If you use xMatters you know all about how important it is to have those integrations working efficiently. We want our incident teams to be well versed in the tools they use to communicate, troubleshoot, and document the incidents.

Like many other organizations, instant messaging and collaboration tools are central to our communication. We use Slack as our primary tool for instant messaging. Since we spend so much time in Slack, it’s a natural place for us to launch our incidents. We’ve evolved how we kick off incidents in the last few years and developed a SlackBot to launch incidents. Slack is where we gather the team and begin troubleshooting.
Two ticketing systems play a key role in our incident process. For customer communication we use Zendesk, and for internal communication we use Jira. We encourage customers to open tickets so we can communicate directly with the people impacted. Jira allows our technical teams to document progress and results. The Jira ticket is also a launch point for post-incident activities. Defect resolution or changes related to the incident are tied to the master Jira ticket, providing context for any work that results from an incident.
The two ticketing systems work together to track issues and keep both xMatters technical teams and customers up to date. In post-incident review, we use the activity in both tickets to build a more complete picture of how we addressed and resolved the incident.
We’re also making use of video conferencing services like Zoom, WebEx, or our own voice conferencing services. Technical teams can collaborate in real time while the scribe tracks progress in the Slack channel. With conference recording, we can save the incident work and review it later.
Workflows and xMatters
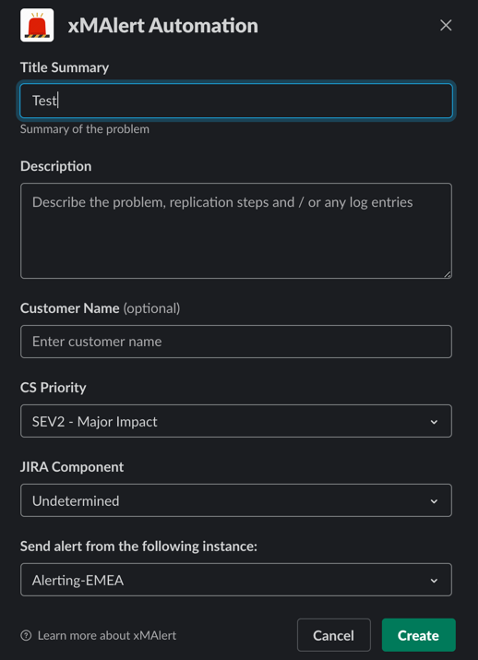
xMatters Alert Automation
There’s a common concept in technology to not rely on your infrastructure for your own incident management. In most cases this holds true; you don’t want the services that run an incident to be impacted by the incident. We leveraged our regionalized architecture and created dedicated regional incident management instances. Now we launch an incident from an alternate region, ensuring that that we can always respond effectively.
Getting the incident process started quickly is very important. You can lose precious minutes if launching an incident is complex. To address this we wrote a simple SlackBot to launch our incident workflows. xMatters then automates the setup of the incident.
The SlackBot allows us to define an incident summary, description, reporter, severity, and information about the service that’s impacted. The bot also allows us to select which instance launches the incident. If there’s an incident in North America or Asia Pacific, we would launch from our European instance. The three incident instances – one each in North America, Europe and Asia Pacific – ensure that we always have the ability to start an incident. Once the incident reporter clicks “Create,” the workflow processes the incident.

xMatters incident management workflow
We use a pretty simple workflow to link all our incident management tools together. It works through the following steps to setup the incident:
- Find the Jira user as the reporter set to the person launching the incident.
- Create a Jira ticket, this ticket becomes reference for all information related to the incident.
- Create a master Zendesk ticket, all customer reports will be aligned under this ticket.
- Link the Jira and Zendesk tickets.
- Create a Slack channel for communication.
- Post links to relevant runbooks (Incident Commander, Support Lead, Scribe).
- Invite other relevant bots to Incident channel.
- Notify relevant teams based on Incident category.
- Post Accept or Decline messages from recipients.
These steps set up the environment to manage the incident. The team is now ready to begin working on resolving the incident.
Managing different categories of incidents
You’ll notice that the workflow has a switch step near the end. This step is meant to notify the right group of SMEs to work the incident.
All high-impact incidents can be reported as Critical or High Impact from a customer perspective, but the category is invisible to the customer. Customers can report an incident by submitting a request through our web portal or contacting support via the phone. If you contact support via the phone the support engineer will create a ticket on your behalf.
If there is an incident already in progress, the ticket is linked to it so we keep track of all impacted customers.
There are three internal classifications that xMatters uses to escalate incidents:
- Major incident – used when services have been severely impacted and a large customer base cannot effectively send notifications or access xMatters. In this classification it’s difficult to determine which service is impacted or there’s a requirement for a wide skill set. The core team and all service teams are notified.
- Severity 1 – uses the same criteria as a major incident, but in this case the impact is known to be to a single service. The core team and the impacted service team are notified.
- Customer Severity 1 – the criteria for these incidents is different, the incident impacts a single customer and there is no indication of a widespread outage. When these type of issues are reported, support takes the lead and connects with service teams as required.
We planned for the ability to escalate or deescalate between the different classifications, gathering more service teams as required and working directly with customers to resolve an issue that’s specific to them. This process provides maximum flexibility to resolving incidents efficiently.
We derived a huge benefit from approaching incident management in the way described in these blogs. Working through the fundamentals we discussed in Part 1 allowed us to clarify our goals and come to an agreement on what incident management is for xMatters. In addition, we gained a common vision of incident management across all teams. The operational plan described in Part 2 gave us a common process to follow and helped us put all the tools together in a workflow. We were able to meet the needs of the different teams who respond to incidents.
The process helped us make sure we have our incident management tools ready and everyone understands their part in the resolution process. Formalizing three key roles (Incident Commander, Scribe and Support Lead) removed overhead. We are now able to hit the ground running; we spend much less time getting ourselves organized. Evolving technical capacity has greatly reduced our resolution time. We have consistently met our goal of mitigating customer impact within 15 minutes of incident start. Starting to work on an incident takes no more than two minutes.
One last thing
We can’t forget the last fundamental: practice. We practice our incident process once a week. From practice we learn what works and what we can improve. We take away something from every practice session or live incident. Everything we learn helps us improve the incident process or the product itself.
Getting here was a lot of work, but the investment in time and effort has been well worth it.
Thanks for reading! Please check out workflows we use for our customers, and learn more about workflow and process automation.