How To Choose Incident Management Tools

Categories
Incident Management
Incident management tools play an important role in modern DevOps, but developers and DevOps teams do not always understand why. A common attitude is: “Why would we need another app? We already have logging, monitoring, and alerting set up on our systems, so we’ll know right away if something goes wrong.”
But in modern applications composed of interdependent containers and microservices, a single failure often cascades to other services. Traditional alerting is a poor match for modern cloud applications because cascading failures can trigger an avalanche of alerts to the entire Ops team — making it difficult to determine what caused an outage or who should be assigned to fix it. And typical monitoring tools typically only notice when services are actually broken. They don’t see the anomalies and patterns that might tell you something is wrong before an outage occurs.
In contrast, modern incident management tools work with data coming from your monitoring tools — such as metrics, logs, and traces — to filter alerts and proactively spot problems. These incident management tools merge incident data from multiple sources and notify the right people immediately. This helps DevOps teams diagnose and resolve incidents as quickly as possible.
Important incident management work happens post-incident too. Postmortems and root cause analysis help teams to determine how to prevent similar incidents in the future or at least solve them more quickly if they do occur.
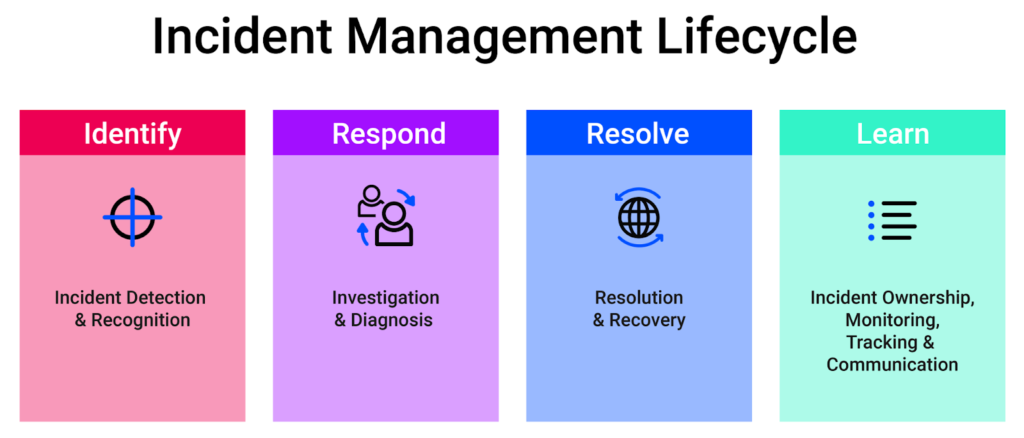
But how can you identify a strong incident management tool? What are the key features to look for? How do you identify core capabilities? Read on to find out.
Important Incident Management Features
Let’s take a look at some key features to consider when choosing an incident management tool.

Incident Response Automation
Automation should be your primary driver when picking an incident management platform. A 2020 research study by xMatters unveiled that 72% of teams spend over half their time resolving issues, and of those respondents, a quarter admitted to spending more than 80% of their time resolving issues. This is an exceptional amount of time spent on resolution, and it drags down fast-paced competitive businesses that should be focused on creating value, not manually addressing issues.
A platform that lets you define automated workflows to resolve incidents quickly will work in your team’s favor, as it frees up time from manual incident resolution processes and can identify issues before they cause outages.
Consider a case where requests to your site are failing because your web servers are overloaded. Your incident platform should let you easily define a workflow like:
- A monitoring tool like New Relic logs the error.
- Your incident management platform notices the error and logs an incident event.
- The person who’s on-call to handle this scenario is automatically notified.
- The notification message offers the responder an option to trigger an Ansible task, for example, that automatically spins up web server VMs to increase capacity by 25%.
- The workflow posts remediation details to a Slack channel and opens a Jira ticket recording what went wrong and what was done to fix the problem.
If you’re looking at an incident management platform that can’t do all this, you should keep shopping.
Incident Identification
You can’t call it an incident management tool if it doesn’t identify incidents quickly and reliably. An incident can be an event big or small and can include everything from a system outage or backup failure to pages loading too slowly or links not working.
Any incident management tool you choose should include automated incident identification. It should also integrate with all of the monitoring and alerting tools your team uses — and any you think you might use in the future. Incident identification depends on plenty of good data, and if an incident management tool can’t ingest all of the monitoring and metrics your apps and services generate, it’ll have a tough time noticing when something goes wrong.
Alert Filtering and Suppression
An enterprise environment can quickly create larger volumes of alerts, so having a filtering and suppression capability is no luxury. This dramatically improves incident-handling efficiency by avoiding information overload and saturation. Alert filters ensure vital information reaches the right people and that the alert won’t be lost among low-priority alerts.
Automated alert filtering can also identify actionable and non-actionable alerts. While every alert will be traceable and available for auditing purposes, there should be a focus on the alerts requiring a specific action.
Alert Correlation
Incident management software typically ingests monitoring and alert data from multiple sources. This is great — as long as the software recognizes that a single incident often causes changes across all of your data sources. If one of your services experiences outages, you don’t want your incident management platform reporting three outages just because the single service outages showed up in three of your monitoring tools.
Automatic event correlation solves the problem by intelligently recognizing that multiple events are part of a single incident and then grouping them into a single incident report. Not only do you benefit from fewer redundant alerts; you also get a detailed timeline of every event that contributed to the incident, making it easier for incident responders to determine the root cause.
On-Call Management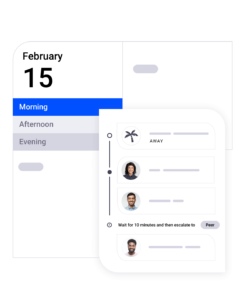
Effective on-call management is an overlooked part of incident management and resolution. Without it, every major incident turns into an all-hands fire drill because there’s no way to quickly determine which personnel are currently on-call and qualified to solve the specific type of incident that’s occurring.
Look for an incident management solution with advanced on-call management capability. An ideal platform lets you set up on-call schedules and skill sets so you’re not scrambling to find and contact the right people during an emergency.
Incident Communication
Notifications used to be mainly email-based but nobody watches their inbox constantly, so it’s easy for important messages to get buried extending response times significantly. IT Operations teams now rely more on real-time communications tools like phone calls, chat, and text messages, to ensure everyone has the necessary details about incidents instantly.
Besides informing the technical teams, it’s beneficial to notify business stakeholders. For example, you may need to inform a DevOps manager about deployment failures. And if you’re experiencing a systemwide outage impacting all of your customers, you probably want to notify the CTO too.
Look for a tool that fits into your existing workflow by integrating with your team’s messaging platform. Your Incident management solution should be able to determine exactly who to contact for any given incident type and severity – and offer integrations with tools like Teams, Slack, and Jira to help reach team members where they conduct their daily work.
Taking it a step further, consider looking for incident management software that supports integrations that automatically update your system status page when one of your services experience an outage. While internal incident communication is important, communication with customers is vital, too. It’s frustrating when you’re trying an app or API that’s experiencing an outage but its status page shows green lights across the board.
Postmortem Incident Analysis
Finally, look for a postmortem and incident analysis feature. Your incident management tool should help you understand what went wrong and how to prevent it in the future.
Look for a solution that offers detailed post-incident reporting — including a timeline of events that contributed to the incident, a list of people who were notified, who responded, how the incident was resolved, and the ability to easily share this information. A good post-incident report should also provide follow-up information and link to additional documentation such as in-house or public articles and documents that help find a solution.
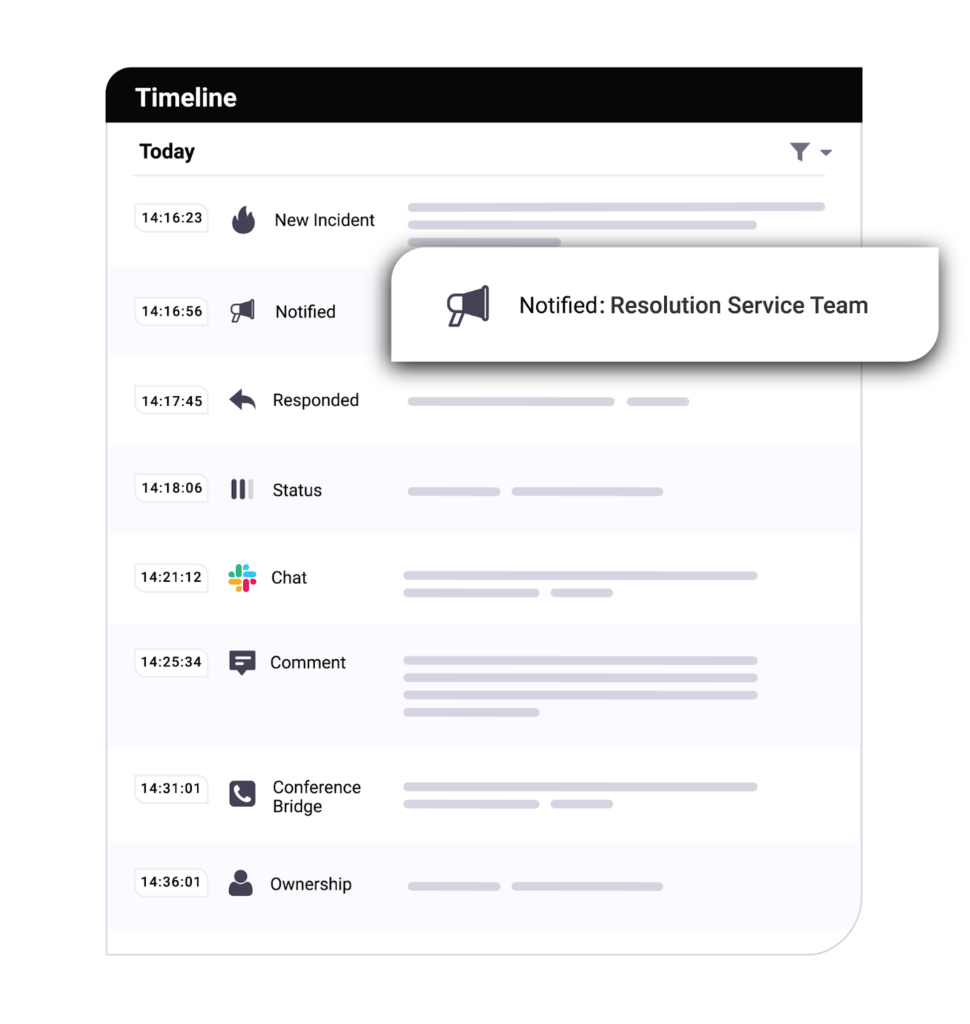
Together these features make it easy to conduct effective incident postmortems and analysis to prevent similar incidents from happening again.
Next Steps
Managing fast-paced delivery, continuous deployment, and/or complex IT environments can be daunting, and with lots of room for error. Microservice-centric apps running in the cloud need more than just monitoring — they need robust and reliable incident management.
Incident management tools can seem intimidating if you’re new to the space. However, as we’ve seen, they actually simplify the lives of DevOps teams by providing timely and relevant notifications and communication and integrating automation throughout your incident management workflow. They reduce the workload when incidents occur and help resolve incidents quickly, giving teams more time for higher-value work.
xMatters’ service reliability platform delivers all the functionality listed in this article, as well as plenty of other unique features that help businesses address incidents effectively.
To learn more about how xMatters could manage incidents for your organization, address alert handling, and provide guided communications and notifications, schedule an xMatters demo. It’ll give you a chance to see an incident management tool in action and ask our xPerts any questions you might have.