Matching Incident Management Roles and Workflows to Process

Categories
Incident Management
My first blog in this series was on five fundamentals of an incident management process. Well, like other dynamic SaaS platforms, our technology and codebase constantly evolve. At xMatters, like any other SaaS platform, our technology and software evolve often. We needed to regularly review our incident process from the ground up, try new approaches, and include new resources that we needed to review our incident process and our incident management roles and responsibilities to ensure that they were current and covered the needs of our environment.
We used this opportunity to look at the process from the ground up, try new approaches, include new resources, and add workflow and process automation. This isn’t to say that the existing process was bad, but like anything worthwhile it needed to evolve.

Visit the xMatters Trust Site
You, Me, & GCP
Since 2018 we’ve made subtle but important changes to our architecture, and to how we approach deployments. First, we completed a move from our own hosted data centers to Google Cloud Platform (GCP). This gave us a more dynamic architecture which could be scaled to customer needs much faster than a traditional datacenter.
We also moved to a service-based software architecture (SOA), which can scale to limit the impact of an incident to certain services and customers, leaving others unaffected. We expected to have fewer incidents after moving to a more stable architecture with Google Cloud; but if the scope was going to change, we had to adjust the incident plan.
Redefining our incident management framework
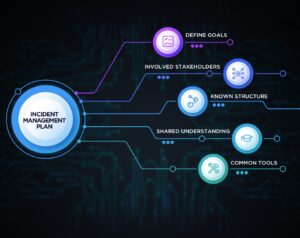
Based on these assumptions, we began to revamp our incident process, using the fundamentals mentioned in the previous blog as a guide.
It may seem obvious, but the goal is to fix what’s broken. Our existing process needed some massaging to fit our new architecture. We started with a desire to improve our overall response time by addressing ease and clarity. We knew that responsiveness from our incident teams wasn’t an issue, as the teams have always gathered within minutes.
We had two challenges:
- Determine quickly whether there was an incident in progress
- Enable response teams to organize on the fly and provide an incident timeline to help at key decision points
Determine whether there is an incident in progress
We had to clearly define the severity criteria for each incident type. We reviewed our existing severity structure and adapted it to take into account SLAs, response scope, and customer needs.
Our policy at the time defined incident scenarios. This was useful when there was a limited set of things that could go wrong. However, the new architecture added more interaction between GCP and software services. We determined that it would be useful to define incident severity based on impact and customer urgency, then map to our documented support policy.
This small but important guidance clarified the conditions for incident severity while removing any grey areas. When this update was implemented, we found that it decreased the time between incident discovery and gathering an incident team.
Incident management roles and responsibilities
We looked at the various groups that play a role in incident management and resolution. They were surveyed for their thoughts on what was working well and where we could improve the process.
Through this exercise we discovered that most of our incidents didn’t need large teams. Quick identification let us roll out smaller teams based on the impacted service. A smaller team allows for more focused work with fewer distractions, yet there were some roles that needed to be available for every incident (shown here in order of involvement):
Incident Commander provides leadership

Focuses solely on organizing the team, ensuring timelines are met, and determining resolution steps.
Support Lead keeps customers engaged

The support lead relays why the incident was called, provides initial testing, and details current impact at the start of the incident. While the incident is in progress, the support lead communicates with customers and stakeholders outside the incident team. The support lead also coordinates testing and advises the incident commander on the current state as needed.
Scribe documents progress

While easy to overlook as it’s more of a documentation role, the scribe becomes invaluable when reviewing the incident and building a root cause analysis. Don’t ignore the value of this role!
Subject Matter Experts
With the standard roles defined and present, technical experts can focus on investigation and resolution unencumbered from organizing the response.
We determined that providing an incident timeline and runbooks allowed the incident team to stay coordinated. The runbooks helped the key roles quickly set up the incident and provided timing for decisions. Structuring incidents with a series of easily defined steps adds a known element that helps minimize overall effort while maximizing focus.
Once the base roles were documented and structured, individual service teams began to create their own runbooks that included links to tools, dashboards, and scripts to further reduce cognitive load during an incident.
Incident Commander tasks

At incident start:
- Joins the incident and declares her role
- Determines the summary of the issue
- Confirm roles
- Elect a scribe
- Verify that a support engineer or support lead is present
- Ensure video conference is established and set to record
- Determine if the subject matter experts are on the call
- Work with Support to notify additional team members, if necessary
- Provide an impact summary to the support engineer or support lead
Support Lead tasks

Identify the incident:
- Determine if there is an active incident
- Initiate the incident in Slack
At incident start:
- Provide an initial assessment of the issue, including customer reports
- Work with the Incident Commander to notify additional team members, if necessary
At regular intervals:
- Test effectiveness of remediation efforts
- Communicate status updates to impacted customers
Scribe tasks

At incident start:
- Note who is fulfilling other incident roles
- Note a description of the incident
- Note which development teams have joined the incident
During the incident:
- Capture a list of SMEs and their areas of responsibility
- Capture important technical milestones:
- SME suggestions
- SME troubleshooting results
- Incident redefinition
- Updates from Support Engineer or Lead
Every 15 minutes:
- Publish an internal incident summary, including:
- Current impact statement
- Any relevant incident state changes
- Technical milestones
Revamping incident severity
With this revised incident management process in place, we then had to apply our basic process to different use cases and different incident types, with workflow and process automation. After all, we typically don’t respond the same way to a major customer-impacting incident the same way we do to an incident that only has internal impact. But I’ll discuss all that in my next post.
Workflows from the real world
Please check out workflows we use for our customers. We’ll be adding more going forward. See xMatters Workflows.