How We Respond To An Incident At xMatters


Here at xMatters, service reliability is at the forefront of everything we do. We’ve been detecting, managing, and resolving incidents as our bread and butter for more than twenty years. Competing with that paradigm is the goal to innovate and iterate, with frequent feature rollouts and bug fixes. If you’ve ever built software, or simply used it, you know that the conflict between these goals is real and that things will break. Mitigating that risk requires process and diligence.
The processes and tools we use to maintain a high level of service have seen many different iterations over the years but the core idea has always been the same: detect and fix issues before our users are impacted. So, how do we do it? In short, xMatters uses xMatters so you can use xMatters without interruption.
Detection and Initiation
Incidents at xMatters come in all shapes and sizes, but they generally follow one of two paths. These paths depend on the detection mechanism and the resulting severity of the incident. We employ several different monitoring tools to detect goblins: Prometheus, Runscope, SignalFX, Splunk and others are all keeping watch, and each can trigger an xMatters workflow when something goes awry.
Service-level incidents
Using standard SRE practices, xMatters service teams have defined and implemented monitoring and alerting mechanisms for key service metrics. We monitor all sorts of things, from the mundane (is service ‘x’ up? Is service ‘y’ experiencing resource limitations or contention?) to the more interesting (elevated error rates? Is event traffic approaching an SLA violation?).
Each of these monitored metrics can trigger an xMatters flow to engage the relevant service team in the event that the goblins have invaded. One such workflow we use is quite simple and consists of an HTTP trigger to parse and enrich inbound metrics data, a create incident step, and a create event step.
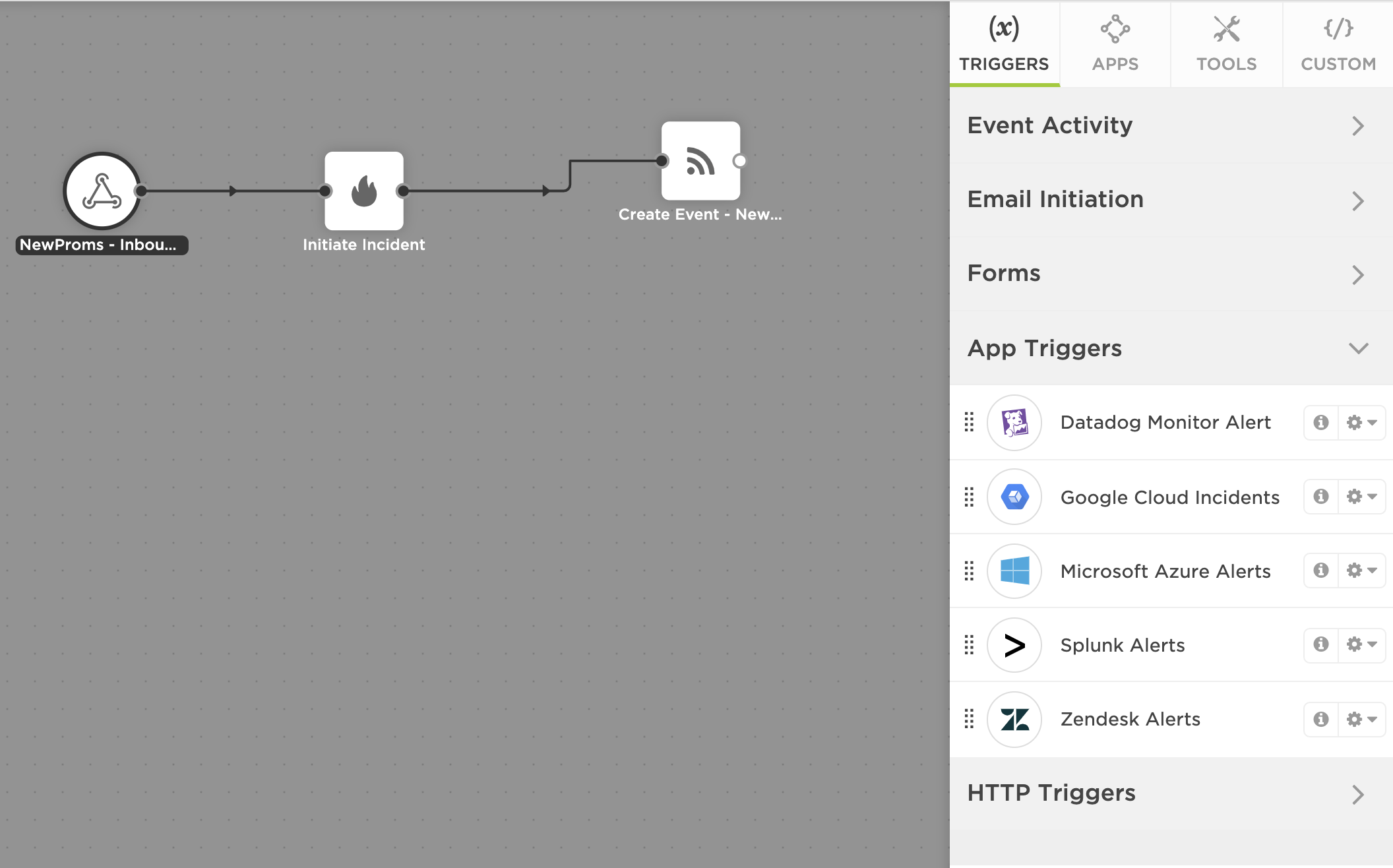 Notification content for these incidents includes playbooks to follow for simple remediation, allowing most incidents of this nature to be resolved quickly by a single xMatters engineer without an impact to end users. If need be, responders can seek out teammates using “Add Resolvers” on the incident console, and quickly collaborate to resolve the issue. However, sometimes these incidents are indicative of a larger problem requiring greater coordination.
Notification content for these incidents includes playbooks to follow for simple remediation, allowing most incidents of this nature to be resolved quickly by a single xMatters engineer without an impact to end users. If need be, responders can seek out teammates using “Add Resolvers” on the incident console, and quickly collaborate to resolve the issue. However, sometimes these incidents are indicative of a larger problem requiring greater coordination.
Severity-1 and Major Incidents
Elevated error rate? Event or notification queues growing faster than they are being processed? Most of the time, these issues occur due to end-user activity. A bad script in a flow designer workflow? Errors! An integration runs amok, causing event flood? Backlogged queues!
At first, these pesky issues may seem like nothing, but they can be a sign of a bigger problem. When this happens we tend to require human involvement to determine the correlation between disparate incidents or to simply determine the scale of the problem. This is where our more advanced incident flows come into play.
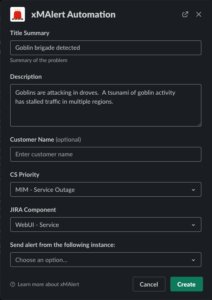 Initiating a major incident, or escalating an existing incident, sometimes requires a person to make a decision. They need to consider what’s gone wrong, how widespread the issue is, and how many users are impacted. Our monitoring enables us to answer those questions and decide if we have to escalate to a major incident very quickly. Once that decision has been made, any xMatters personnel can use our homemade bot from Slack to get things rolling.
Initiating a major incident, or escalating an existing incident, sometimes requires a person to make a decision. They need to consider what’s gone wrong, how widespread the issue is, and how many users are impacted. Our monitoring enables us to answer those questions and decide if we have to escalate to a major incident very quickly. Once that decision has been made, any xMatters personnel can use our homemade bot from Slack to get things rolling.
Once the initiator executes the Slack slash command, they are presented with a simple dialog box that allows them to specify relevant details for the incident. Those details enable us to assemble the right resolver teams immediately via a custom xMatters workflow, while simultaneously creating all necessary tickets and collaboration channels needed to resolve the incident.
Let’s take a look at the major incident workflow in more detail.
Major Incident Workflow
The xMatters major incident workflow has several steps which perform the following functions to allow full automation and coordination of the many tools we use to resolve an incident.

Click to enlarge the image.
- Collect the details for the JIRA user that’s creating the incident.
- Create a JIRA ticket using the identified user.
- Create a Zendesk ticket, for internal use by customer support.
- Link the JIRA and Zendesk tickets.
- Create an xMatters incident.
- Create a Slack channel.
- Create a Zoom meeting
- Invite several bots to the Slack channel
- Post details of the incident to the Slack channel with all prior details (known incident details, the xMatters incident ID, ticket IDs, conference call information)
- Create an xMatters event to notify customer support representatives and our engineering services teams.
- Post final details to the Slack channel
That’s a lot of steps, and they are all steps that were done manually at one time or another in our team’s history. By using Flow Designer, we’ve taken a multi-step process and turned it into a single step: a slash command in Slack with a few simple inputs to populate fields, enabling the first responder to initiate our incident management process. What used to take minutes and could be prone to errors is now performed flawlessly in seconds.
Resolution
Once all tools are communicating and the relevant service teams are notified, we use well-established playbooks to investigate, mitigate, resolve, and document the incident while providing periodic updates to stakeholders. We have four primary roles within Engineering and each of them has a predefined playbook detailing their responsibilities during an incident and how those obligations can be met:
- Incident Commander: coordinate the effort required by all involved parties to bring the incident to resolution.
- Scribe: document important incident details and decisions made throughout the course of the resolution process.
- Support Lead: coordinate customer support responsibilities, ensuring timely stakeholder and customer communications.
- Resolvers: xMatters Engineering personnel dedicated to identifying and resolving technical issues.
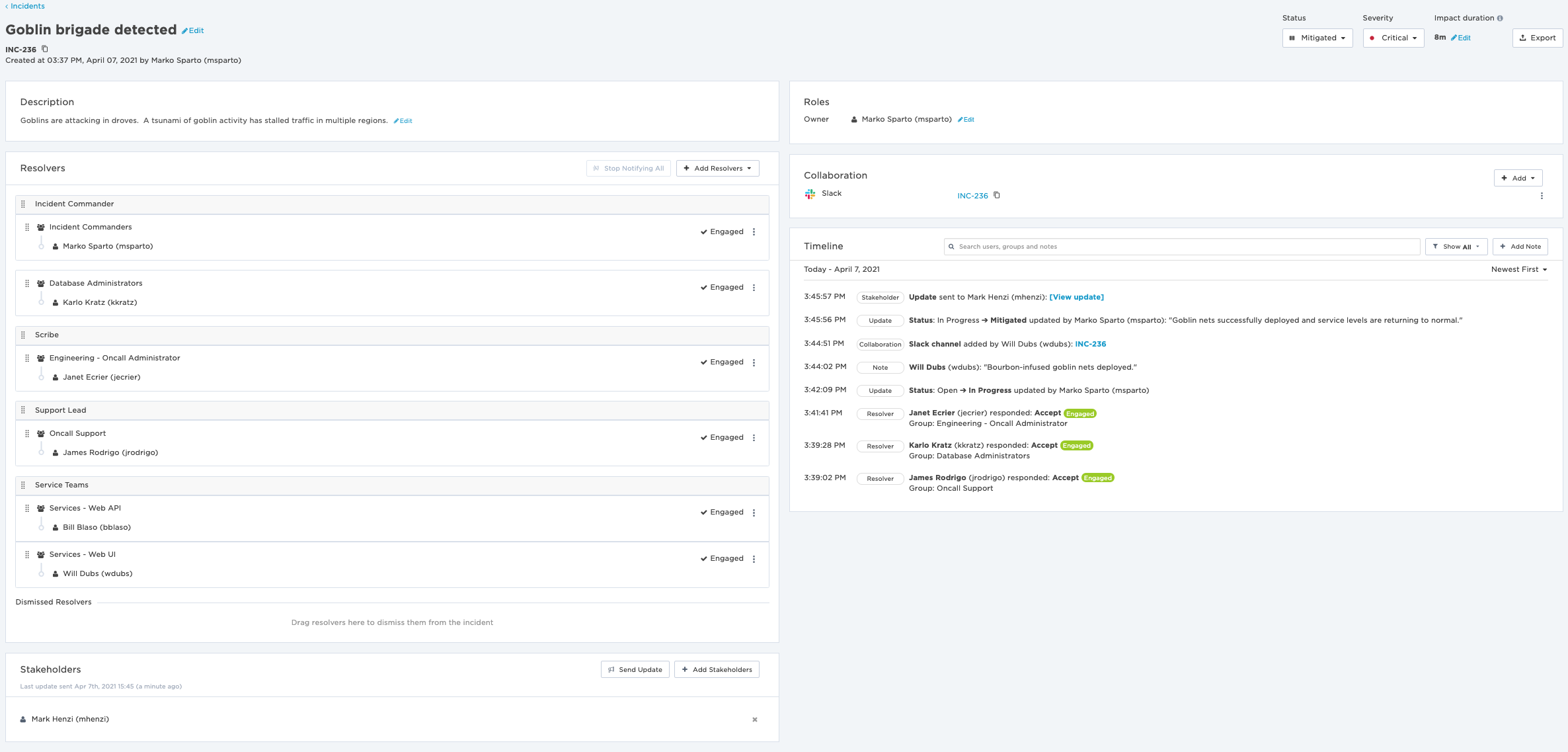
Click to enlarge the image.
All incident participants have the ability to access and use the powerful adaptive incident management console to perform their duties.
The incident commander can organize the resolvers into specific roles using drag and drop, and custom labels so everyone can see at a glance what everyone else is working on. Resolvers can seek help from subject matter experts via the “Add Resolvers” button. Scribes can take incident notes directly in the incident timeline, and support personnel can leverage the stakeholder feature (coming soon to a production xMatters instance near you!) to provide timely updates to external stakeholders. Links to Slack channels are readily available on incident creation, and other collaboration methods can be added via the console itself.
Over the lifetime of the incident, the incident commander can modify the status or change severity as needed, with all changes detailed within the incident timeline. At xMatters, we use a combination of timeline notes and Slack data to document incident details for use in post-incident analysis activities.
Finish It
Once the incident is mitigated, most xMatters incident commanders will elect to dismiss any incident resolvers that have completed their work, while working with the remaining team to banish the last few goblins. As soon as a permanent solution has been identified and implemented, the incident is marked as resolved and we move into the post-incident phase.
No incident is truly “finished” until a full root cause analysis can be completed and documented, with action items and potential improvements identified. Again, we use xMatters to facilitate that work, but that is a tale that will be detailed in a future article. In the meantime, if you need some help to improve your postmortem process, here are several best practices to ensure it’s effective and painless.
Ready to try out xMatters?