Best Practices for Painless Incident Postmortems

Categories
Incident Management
We live in a digital world, and it’s backed by increasingly complex digital systems. Whether running on-premise, in the cloud, or distributed across the Internet of Things (IoT), applications are more complicated than they used to be. Outages are challenging, as they occur in a constantly-changing interconnected environment where a simple configuration error can cause a worldwide support incident. In situations like these, structured incident postmortems and follow up are critical — you don’t want to make the same mistake twice.
But what is an incident postmortem, anyway? Put simply, it’s a structured review process that follows a severe outage or other technical error that caused significant disruption for your app’s users. A good postmortem provides DevOps teams and managers:
- An understanding of the incident’s root cause(s).
- A detailed timeline of when each step in the incident happened from the time it was first noticed to the time it was resolved.
- A set of action items the team can implement to prevent the same thing from happening again.
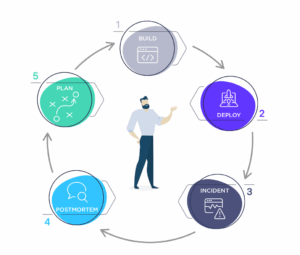
A postmortem is a critical step of an always-on service.
It’s worth noting that not every incident or outage requires a postmortem. In general, you’ll want to save postmortems for serious incidents that last for a long time, impact a large number of users, have a significant financial impact on the business — or some combination of these. If the incident only impacted a few users or was resolved before many users noticed anything was wrong, it might not be worth doing a postmortem, especially if you can make changes in your app or your infrastructure that prevent a recurrence.
When you do want to conduct a postmortem, however, you’ll need to record all aspects of an incident. The postmortem requires information about how your team recognized the outage, how they handled it, and what remedial steps they took. Manually reconstructing the sequence of events post-incident can be daunting and time-consuming. Worse, you often lose critical information that could have helped pinpoint what went wrong.
Despite the challenges, using automation to record these details can make incident postmortem review painless — or at least less time-consuming and more accurate! xMatters 2020 State of Automation in Incident Management study revealed that while 73.9% of support and development teams reported performing cross-team collaboration after incidents, only 14.5% of respondents use any form of automation for postmortems and root cause analysis.
In this article, we’ll show you how setting up automation helps you access the information you need to conduct effective postmortems.
Why Conduct an Incident Postmortem?
When incidents or outages occur, your primary focus is ending the outage and getting services up and running again. Root cause analysis comes afterward, when everyone wants to know what happened and why.
Incident Postmortems ensure that details are documented and the team understands the root causes. You then take preventative actions to reduce the impact and likelihood of a recurrence. By investing some time upfront to prepare for postmortems, you help avoid wasting time and effort (and losing sleep) in the future.
Conducting a postmortem can be uncomfortable — nobody likes to be in the hot seat. The process works best if everyone on the team resists the natural tendency to point fingers. Create a positive culture to ensure postmortems are a learning opportunity, focused on improving performance moving forward.
How Incident Postmortems Work
While postmortems differ between organizations, there’s generally a common sequence of steps:
- Choose participants
- Source documentation
- Record actions
- Perform root cause analysis
- Identify key lessons learned
Let’s look at each step.
1. Choose participants
The first step is to decide who will be on the team conducting the postmortem. If possible choose someone to lead the incident postmortem who wasn’t directly involved in the event, as they’re usually able to approach the process with less bias.
The exact composition of the team depends on the size of your company and the nature of the incident. If you’re a startup and the incident caused an outage impacting all customers, it might be appropriate for the CEO or CTO to be part of the postmortem.
If, on the other hand, you’re a Fortune 500 and the outage involved only a subset of users, it might be best to limit the postmortem team to developers and SREs. The postmortem team can then report the results to their managers, who can then report up the chain of command as needed.
2. Source documentation
Capture incident details and collect data. Explain what happened, which services were impacted, and other contextual information. Many systems produce log streams and even analysis. This information is usually gathered automatically or if not, must be manually harvested.
3. Record actions
Document the actions taken to diagnose, analyze, and resolve the incident. Be as specific and step-by-step as possible so that others can duplicate the actions.
An excellent step here is to create an event timeline. Detailed log streams are useful, but picking out relevant items can be daunting — the ability to filter the timeline aids in understanding at both a high and a low level. Tools like the xMatters visual incident timeline can give you a detailed understanding of what happened when.
4. Perform root cause analysis
The purpose of a root cause analysis is to discover the exact problem that triggered the incident. In many complex scenarios — and what major incident isn’t complicated? — a sequence of multiple errors results in an actionable incident.
To perform a meaningful root cause analysis, you must capture the initial source of the failure and any useful information about when and why it occurred. A team knowledgeable enough to dig into details should identify and document the root causes.
5. Identify key lessons learned
It would be great if we could always determine exactly what failure or sets of failures caused an incident. But anyone who has spent any time slaying incidents knows that problems – and solutions – can be highly nuanced. Sometimes you’ll have to settle for identifying a class of errors that have varying details, but can be grouped thematically.
Documenting the key lessons and making them available can be a challenge. People and systems change over time, but many problems stay the same, so documentation is crucial. Look at it as part of a continuous learning process; a postmortem is only worth the time you spend on it if you use it to prevent the same kind of incident from happening again. Writing down the postmortem’s key lessons and integrating them into your processes helps the entire company learn and improve.
Most of these steps require data and usually, this means sifting through notifications, logs, and disparate systems to gather it all together. Once you have all this information, what do you do with it and how do you make it available in the future?
Conducting Effective Postmortems with Automated Incident Response and Management
Tracking and managing events and incidents is difficult, and implementing effective postmortems can be even tougher—especially as systems and people scale up. Details can be easily lost or hidden on someone’s desktop computer, in their email, or fragmented between the many messenger apps, bug trackers, and analytics tools used by teams involved in DevOps.
As DevOps has matured, we’ve started to see excellent tools to manage incident response and management. Modern incident automation can tie together event detection, data collection, and response initiation and then automatically drive incident response to the people or groups best able and available to resolve the issue.
But how does that help deliver postmortems?
Any tool that can automate the steps needed to recognize, respond to, and recover from an incident can also record all of the events that occurred during incident recognition, response, and recovery. This lets you skip the boring work of determining what happened when and skip directly to the most valuable parts of the postmortem: figuring out why the incident occurred, and coming up with a concrete plan to prevent it from happening again.
Sounds great, doesn’t it? So let’s dive into the details of what you can expect from an automated incident response and recovery platform and then tie those details back to painless postmortems.
Postmortem automation in action
Let’s dive into the specifics of how an automated incident response platform helps you conduct effective postmortems.
The first and most important feature is integration with your existing monitoring tools. Automated incident response and recovery tools ingest data you’re already collecting and then use it to understand when an incident is occurring. Ideally, your system should have built-in integrations that recognize commonly-used monitoring tools.
This makes postmortems easier because you’ll already have a holistic view of all data related to the incident. There’s no need to go digging through disparate logs and traces because the information is already gathered in one place.
You should also be able to design workflows to determine what constitutes an incident – and what to do when one occurs. This helps ensure that your system isn’t raising false alarms and waking up engineers in the middle of the night.
An extra benefit of customized incident workflows is that the system only records data when an actual incident occurs. This makes postmortems even easier because you can jump directly to the data that’s relevant to the incident you’re working on. No need to waste time separating the wheat from the chaff. With automation pre-configured to collect data, we can be sure that it’s available when an incident occurs. To learn more about incident management tools and workflows, make sure to check out our blog Incident Management Tools and Workflows: Putting It All Together.
Using Captured Incident Data in Postmortems
We’ve seen how an automated incident response tool can be set up to make postmortems easier. Now let’s take a quick look at how that works in practice.
Ideally, an automated postmortem report should include:
- A summary of the incident.
- Any additional details available about the incident.
- A detailed timeline of every event that occurred during the incident, starting with the event that triggered the incident and ending with the incident resolution.
This report can take several forms. Something as simple as a spreadsheet can be useful:

But spreadsheets aren’t the best possible solution. With all of the data gathered about an incident, an incident automation platform should also be able to construct a detailed postmortem report that’s user-friendly and easy to share with others in the organization.
These reports can include a list of people who participated in the postmortem and a timeline, and perhaps even a list of actions to prevent similar incidents from occurring again, with a specific person assigned to carry out each action:
This kind of highly visible, user-friendly postmortem report can help ensure that postmortems become part of your company’s continuous learning process. People will gladly read reports that are easy to find and easy to use. They can even be used as training tools.
In contrast, postmortem reports that are dropped in a forlorn Google Drive folder will probably be quickly forgotten.
Next Steps
Thinking about your incident management processes and systems upfront helps you plan for—and avoid—system degradations and disasters. Postmortem reviews are an essential part of this process and don’t have to be slow and expensive.
Advanced automation tools like xMatters help you organize and automate incident response. They also enable thorough postmortems by ensuring a complete log of events, notifications, responses, resolutions is available. This means you’ll spend less time searching for information and more time fixing bugs, preventing future incidents, and building great new features.
Ready to try out xMatters? Let us show you how it can transform your operations—request your demo today.