CI/CD and Quality Assurance in Software Testing

Categories
DevOps & SRE
Following our earlier thoughts on canary deployment strategies in CI/CD, we’d now like to explore how we can ensure that the software we deploy is of the highest quality while still delivering new features and capabilities directly to our customers.
The Quality Framework

The first stage to ensuring quality software releases is to have a framework in place to validate the software is fit for its purpose. As xMatters operates multiple microservices, architecture quality assurance has to be performed at the service level and at the product level, meaning that some tests will be common across services but not all tests will be relevant for a specific service.
For example, suppose a change to the web user interface requires a new column in a database table. The web server queries the database using the API service, which means that a change to the database needs to be tested against the web server and the API server. Similarly, a change to the API server may impact an endpoint used by the integration service, meaning that tests for the API server must include exercising integration services.
So how can we make sure that our quality assurance framework covers full integration testing and still supports smaller sets of tests that may overlap without repeating code across services during the CI/CD process?
Test Suites
The first stage in the process is to group tests into suites. At xMatters, we group tests by application function. This means that we have suites of tests for our User and Group Management pages, suites for our Messaging functions, suites for Workflows etc.
This means that we can mix and match tests that we want to execute in a particular service deployment. For example, when deploying the back-end services that support our integration platform, running tests that exercise the front-end UI code or the messaging functions is unnecessary as they have no bearing on those parts of the application.
We still need to be able to execute the test suites by service and have the test results feed back into that service’s CI/CD pipeline so that we can easily detect defects and monitor trends in defect analysis (more on this later). But that raises another question: how do we support having multiple services running their collection of tests from a common library within a CI/CD pipeline?
Pipeline as a Library
Using Jenkins as our CI/CD tool, we can make use of shared libraries to write common code that can be shared across service pipelines. Simple examples of this are things like cutting release branches and creating release tags in a common and consistent manner. But, the shared library also provides us with the ability to create shared pipeline code and easily include it in a service pipeline.
For quality assurance, we created a new shared pipeline code that executes integration tests in parallel (to speed up the overall execution time of the pipeline), collates the results, and provides a single report for the multiple suites that are executed as part of that pipeline.
An example of a synchronous shared pipeline library looks like this:
def call(Map args) {
try {
args.testSuites.each { k,v ->
executeOneTest(args, k, v)
}
} finally {
args.testSuites.each { k,v ->
unstash "stash-${k}"
}
allure([
includeProperties: false ,
properties: [[key: 'allure.issues.tracker.pattern'']],
reportBuildPolicy: 'ALWAYS',
results: [[path: resultsPath]]
])
}
}
private def executeOneTest(args, String key, String testSuites) {
node('qa-automation') {
stage(key) {
container('cypress') {
try {
unstash 'qa-automation'
timestamps {
sh """
runTests.sh ${testSuites}
"""
}
} finally {
archiveArtifacts artifacts: 'reports/**/*', fingerprint: true
stash name: "stash-${key}", includes: 'reports/**/*'
}
}
}
}
}
This example iterates a collection of tests in a suite and runs a stage stashing results for each execution, and then collates the results to report to the calling pipeline. Jenkins easily allows you to modify code like this so that it can be parallelized to reduce execution time.
What this gives us is a tool that we can integrate into a pipeline in the following manner:
executeAutomationTests branchOverride: 'main',
credentials: 'regression-uid',
testType: 'cypress',
testSuites: [
conferenceList: 'ConferenceList/**',
deviceManagementList: 'DeviceManagementList/**',
login: 'Login/**',
messaging: 'Messaging/**']
This approach allows us to re-use the logic across multiple service deployment processes without implementing it separately in each pipeline and without having to build logic that handles the complexities of running these suites in parallel, collating the results, and reporting them back to the job.
Instead, we can call this method and pass in parameters to run suites of tests that are relevant to our process, and the call creates a single test report that can be archived along with the job. When viewed in Allure, a full-featured reporting tool that integrates with different testing frameworks, the report looks like this:
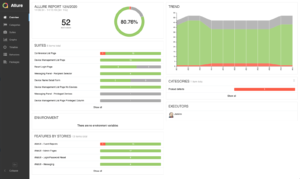
Now that we have the tests embedded into our process, we can use this data to see trends and analyze the results to improve our code quality and the speed at which features are released to production.
Test Result Reporting Framework
With the CI/CD process, we need to know more information about the test case than just whether it passed or failed. From a release perspective, engineers need to know the following information about the tests to confirm the release to the production environment:
- Details about the test case and feature
- The criticality of the test scenario for business needs
- The service owner responsible for the feature
- Differentiations between the failed, broken, and flaky tests as well as known product defects
Here’s an example of how this information looks in the TestNG framework, which we use for our Java-based automation testing:
import io.qameta.allure.Epic;
import io.qameta.allure.Feature;
import io.qameta.allure.Story;
import io.qameta.allure.TmsLink;
import io.qameta.allure.TmsLinks;
@Epic("Mobile API") // Name of the Service Component under test
@Feature("Device Registration") // Details about the feature
@Story("/device") // Details of story that implemented the feature
//Details of the test case ID/Key in Test Case Management tool of all the test cases covered by a given test
@TmsLinks({
@TmsLink("259945"),
@TmsLink("259946"),
@TmsLink("259947")
})
@Test
And this is Cypress, used for our front-end automation:
cy.allure().epic('WebUI - Groups'); // Service Component
cy.allure().feature('Manage Groups')
cy.allure().story('Group Landing Page')
cy.allure().tms('1222564', '1222564'); // Test Case Key/ID in Test Case Management Tool
cy.allure().issue('BUG-16605','BUG-16605'); // Issue Key/ID in Defect Management tool
The Allure Framework tool shows a concise representation of this data in a web report form, allowing us to use a single tool for reporting no matter what service is being tested, and easily integrates the test results to Test Case Management tools like TestRail and defect management tools like JIRA. Providing this kind of metadata information—along with a history of previous test runs—allows the release engineer to easily engage the respective owners to troubleshoot and identify the root cause of any failure. Details about the test case provide valuable information on how critical a given test scenario is to the business needs, enabling engineers to easily make decisions about promoting changes to production in a timely and efficient manner.
Conclusion
QA automation is not a silver bullet or a guarantee that everything will work flawlessly, but it is a key component in ensuring stable and high-quality software releases. It provides a level of confidence that the release has been reviewed against known test cases and reduces the likelihood of introducing regressions into future releases—as the tests know how a function is expected to work.
The tools we have described help us integrate QA into our processes in a simple way—providing us with confidence in our software and data, and allowing us to focus our efforts on critical areas. The reports can be exported into other tools so we can perform additional analysis and provide information to all levels of the organization—from developers who care about the quality of their releases, to managers who are interested in how much automation coverage we have.