How We Created a Great Data Transfer Service from a Hairball Using Google Cloud Pub/Sub

Categories
Infrastructure & Operations
Our original data synchronization became an unmanageable hairball from all of our customers syncing data into our systems. As we investigated solutions, Google Cloud Pub/Sub seemed to have the features we needed. Tim Thompson does a deep dive into it.
Our customers sync a lot of data into our systems. Our original data synchronization became such a hairball I’m pretty sure the YouTube cat cabal had something to do with it. So we decided to start from scratch (pun intended) and implement a new data transfer service, which we ingeniously named the Transfer Service.
When we were thinking about the enterprise-grade architecture of this new Transfer Service, our architect helpfully supplied exactly one diagram to help us out:
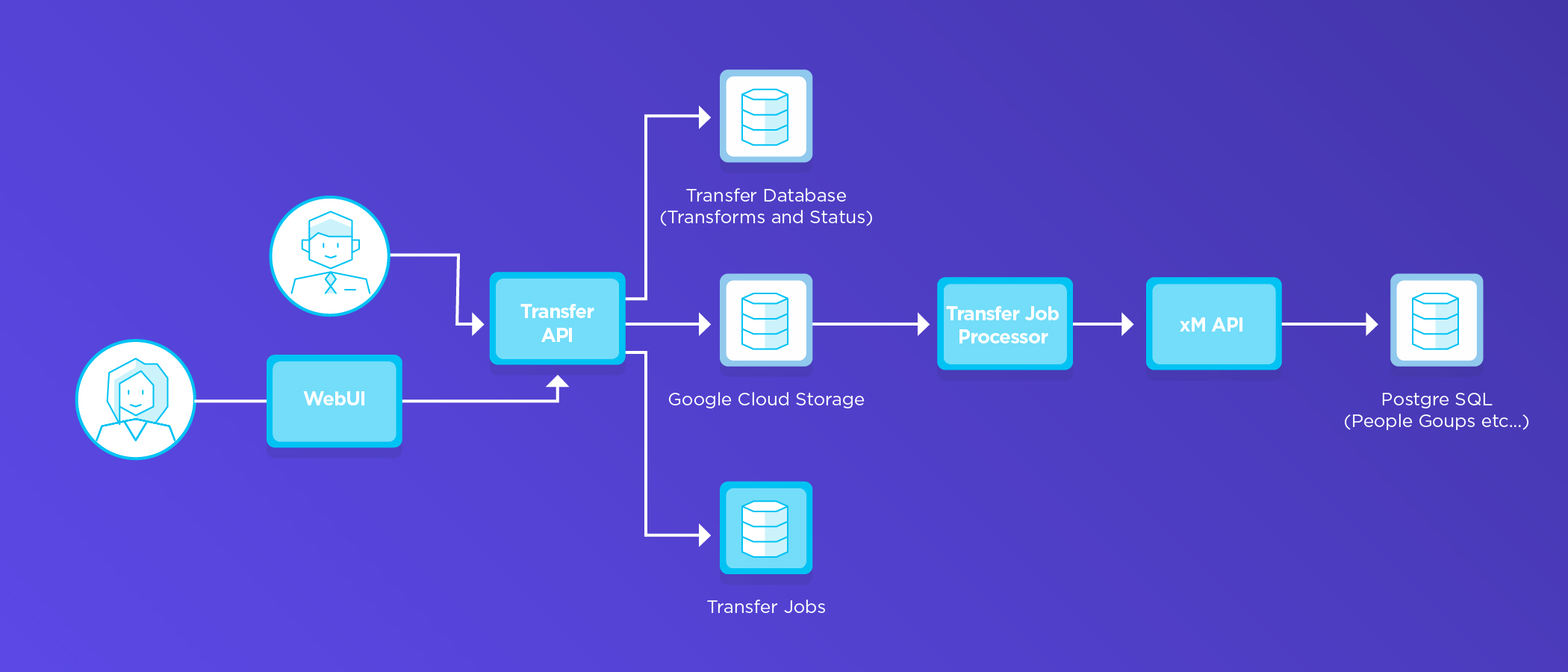
There’s plenty to unpack in that graphic, and as a UI developer I kept trying to imagine what was in all those enigmatic blue boxes. But for this article let’s focus on that “transfer job processor” object, which is a job queue enabling asynchronous processing of, well… transfer jobs. And it would also eventually help scale the service by decoupling the transfer job processor from the “transfer API.”

The right tool for the jobs
As we started thinking through the challenge, we had to make some technology choices. Other dev teams were already using Apache Kafka as a stream processor that can persist messages. Kafka provides delivery guarantees as well as other non-functional requirements such as disaster recovery and fault tolerance. However, using Kafka would also mean managing its infrastructure complexity, which was a complaint we heard from those other teams. It also requires Zookeeper as a distributed configuration management tool.
Other teams were using RabbitMQ, but they told us that the their implementations were less than ideal and they would have taken a different path if they had to do it over again. It seemed like dynamically creating queues was not easy to do in RabbitMQ. And, as with Kafka, we’d have to manage the infrastructure.
We had just started the migration of our service to Google Cloud Platform, so naturally we looked into what functionality Google had to offer. We first considered Google Dataflow, but concluded that it works better for self-contained processing that can be easily parallelized. While it can auto-scale workers, the actual work is done via calls to our API and would not be self-contained in a worker. In a nutshell, if DataFlow scaled to 1,000 workers, we would kill our API.

____________________________________________________
“Our original data synchronization became such a hairball I’m pretty sure the YouTube cat cabal had something to do with it. So we decided to start from scratch.”
____________________________________________________
We (may) have a winner
Ultimately, it looked like Google Cloud Pub/Sub might have the features we needed. Let’s dig into its pros and cons.
The Pros of Google Pub/Sub:
- Google manages the infrastructure: In the absolute sense, this is a big pro, but you should weigh the financial cost. The pricing page states that it costs 0.06USD/GiB/month after 10GiB of traffic. For each transfer job initiated, we publish a small JSON object of metadata to Pub/Sub. Each metadata JSON object was about 578 Bytes, but according to Google, “The minimum billable volume of data per request (not message) is 1 KB of data.” We’d have to be processing more than a million (1GiB = 1^30 Bytes = 1073741824 / 1024 B = 1,048,576) jobs in a month before we started getting charged. For us, this wasn’t expensive for the approximately 1GiB/month of data we planned to store. We calculated that even if we sent all our expected jobs through Pub/Sub, we still wouldn’t be charged – of course, YMMV.
- Ability to create infrastructure programmatically: We could create topics and subscriptions programmatically without having to set up any queues in advance. This makes deployments of new versions easier, as we planned on having a Pub/Sub topic for each version of the Transfer Service. We would then just need to deploy a new version of the service and it would create the Pub/Sub topic and subscription for its own version.
- Ability to limit access to Pub/Sub resources: Setting up Service Accounts for the Transfer Service was fairly straightforward as we were able to create a credential key that could be passed to the correct environment (dev, test, production). Adding the Pub/Sub editor role allowed us to use and manage all topics and subscriptions.
- Built-in disaster recovery: Pub/Sub will keep trying to deliver messages that have not been acknowledged, and we planned on using that to support disaster recovery. If the Transfer Service went down, we could just restart it, begin pulling messages, and start working on the same job again. If we ACK (acknowledge) messages immediately and crash, we would need to recover that message or lose the job.
The Cons of Google Pub/Sub:
Of course, not everything was rosy and there were problems along the way. Here are some drawbacks and things to be aware of.
- Limit of 10K topics: Pub/Sub has a 10,000 topic limit per project. This might seem like more than enough, but early on we were discussing how to achieve fair consumption by having at least one topic per customer. We have thousands of customers and this would quickly exhaust the available topics for Pub/Sub, thereby making fair consumption impossible as “Fair queuing uses one queue per packet flow,” according to the fair consumption algorithm.
- Pub/Sub SDK classes are harder to stub out: Many Google Cloud Pub/Sub classes are concrete and not interfaces, making them harder to stub out when writing unit or integration tests (for example, TopicAdminClient & GrpcSubscriberStub).We could have wrapped each SDK class in our own wrapper, but it’s nicer not having to do that.
- NACK (not acknowledged) semantics are unclear: Let’s say you want to discard the head message and retrieve the second in the queue. Unfortunately, the Google Cloud Pub/Sub documentation doesn’t shed much light on this scenario.
- Multiple Transfer Services Can be Complicated: This may be a function of how we’re using Pub/Sub, but we wanted to run multiple Transfer Services subscribed to the same topic. Each Transfer Service would be getting the same unacknowledged message and would happily start working on the same import job. To overcome this, we implemented another check that would associate the current Transfer Service UUID with a job and only start working on available or orphaned jobs. An orphaned job has a Transfer Service UUID associated with it but is not being processed. For example, when a Transfer Service dies mid-job, it orphans the job it was working on.
- Some messages cannot be retrieved: The Google Pub/Sub documentation states: “A message published before a given subscription was created will usually not be delivered. Thus, a message published to a topic with no subscription cannot be retrieved.” This means that we couldn‘t delete a subscription during a troubleshooting session. We also couldn’t publish a message without a Transfer Service already subscribed to the topic. This can be fixed by having both the producer (for us, our API) and consumer (our Transfer Service) of the queue create a Pub/Sub subscription upon startup.
- Ordering is not guaranteed: This is covered extensively in Google’s Pub/Sub documentation; but basically, if ordering is a show-stopper, you can’t use Pub/Sub.

Mostly a victory that bears watching
Google’s Pub/Sub is a great, flexible, and managed service that allowed us to get up and running quickly with some code churning through jobs. Depending on your usage, the cost can be fairly reasonable and definitely beats maintaining your own queue infrastructure. We’re still not sure if we need to implement fair consumption as it depends on how production companies will use this service. If so, we may be forced to use a different solution. But until that happens, Pub/Sub supports our Transfer Service in production – with a drastic reduction in hairball sightings.
Ready to try out xMatters? Let us show you how it can transform your operations — request your demo today.