Beware What You Don’t Measure

When there’s an IT outage, businesses suffer. The faster you can get the business back up and running, the better it is for all involved. Let’s take a look at some of the best practices for automating major incident management, and place the focus on the importance of measuring time to restore service properly. Let’s take a look at some common metrics, and remember to beware what you don’t measure.
Mean time to repair
MTTR (Mean Time to Repair) is one of the most important and most common metrics for major incidents. Just divide the total maintenance time by the number of incidents.

Read: Five Best Practices to Automate Major Incident Management
It might be intuitive to base MTTR on the time that IT is engaged, but that engagement could start long after the event. You should base MTTR on the time that the business is actually impacted. This measurement takes into account detection and notification, as well as resolution activities.
Mean time between failures
You can figure your MTBF (Mean Time Between Failures) by dividing the total time of correct operation in a period by the total number of failures.
The more time there is between system failures, the more efficient the system is.
So why is it important to understand these metrics, especially as it relates to automation — and more specifically, the importance of measuring time to restore service properly?
For virtually every organization, service outage is a matter of when, not if. Businesses that have a larger MTBF are more productive, by orders of magnitude, than those that have a smaller MTBF.
The importance of automation
Automation of systems that restore service properly provides two very important benefits. First, and foremost, it provides visibility into a dashboard of applications to retroactively start the clock if necessary. This helps to create a larger MTBF, and a smaller MTTR. Second, and just as importantly, it preserves the resolution activities and communications in the system of record for analysis. This helps to keep consistency in the reporting process, which improves a company’s MTTR.
Having said that, sometimes manual processes are more effective than poorly automated ones. Automation is a crucial element of achieving world-class incident management, but taking care of the fundamentals can achieve satisfactory results for most organizations. When xMatters surveyed more than 760 IT organizations in 2018 on automation in major incident management, the results bore this out.
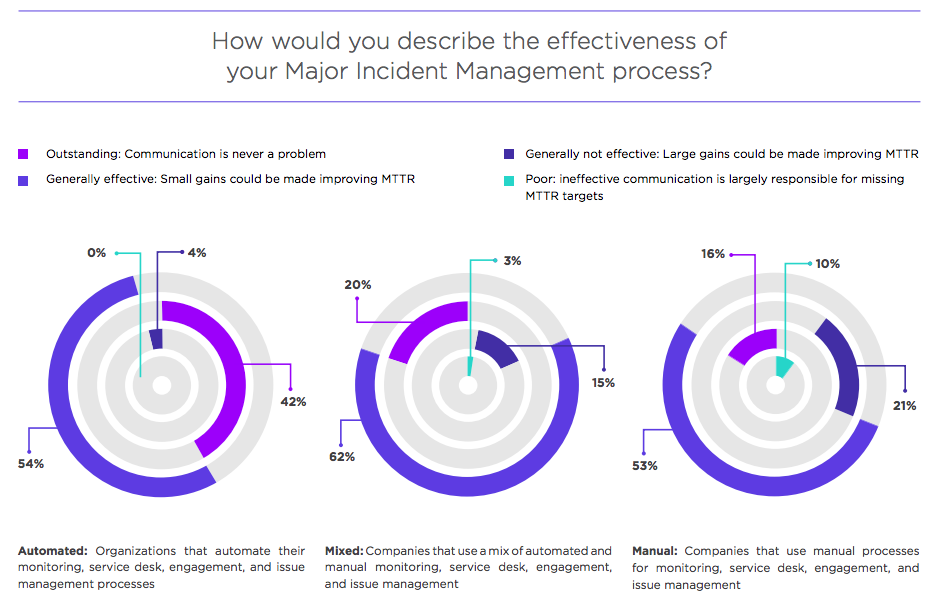
Major incident management effectiveness by automation
The importance of measuring time accurately
When a major incident occurs, the immediate job is to restore the system to operation as quickly as possible. Even if the company executives don’t understand the meaning of MTTR and MTBF, they want to get as many informative updates as possible to have confidence that you, as the IT professional, are doing your job correctly.
So, in summary, what are the best practices for measuring time to restore service accurately?
- Make processes easy through integrations. Your engineers are working in their own systems, and asking them to do work in a new system they’re not used to is intrusive and inefficient. xMatters sends important data to the tools they’re already using and leverages integration an integration platform to connect those systems into toolchains. Engineers can manage incidents, when every minute counts, without leaving the environments where they are doing work. Learn more
- Improve collaboration between your system engineers. Proper IT is never done in a vacuum — when the IT professionals are “on,” it’s important to keep good lines of communication open between all the members of the team. At xMatters, you can open a Slack channel or another chat tool directly from a service ticket or even the mobile app notification.
- Streamline your network troubleshooting. The creation of service management tickets is one of the biggest things that “bog down” the system. Because it’s not a centralized system — in that, oftentimes, there are network engineers that are working through a variety of different tools of varying effectiveness — the more a system can be streamlined, the better your MTTR will be.
- Automate. Design automated response options as much as possible. At xMatters, communication plans dictate IT event management to resolve many situations, saving time and removing risk of human error. Automation is also essential for accurate reporting. Automation also keeps network diagrams and contact information up to date to improve response and resolution times.
- Close the loop. When service has been restored, xMatters stores chat transcripts and other records of event resolution in the system of record, whether a service desk like ServiceNow or an issue management tool like Jira.
It’s imperative to note that while automation solves a great deal of problems, it is not the be-all and end-all for MTTR. Indeed, automating all the processes — and, indeed, eliminating the human capital involved in IT — is nothing short of disastrous. However, the right balance between automation and the curation of manual work will do wonders to improve the MTTR, and help to accurately measure time to restore service properly. In the xMatters survey, manual processes proved more effective at identifying the right people than a mix of manual and automated ones, which can be messy if not designed correctly.
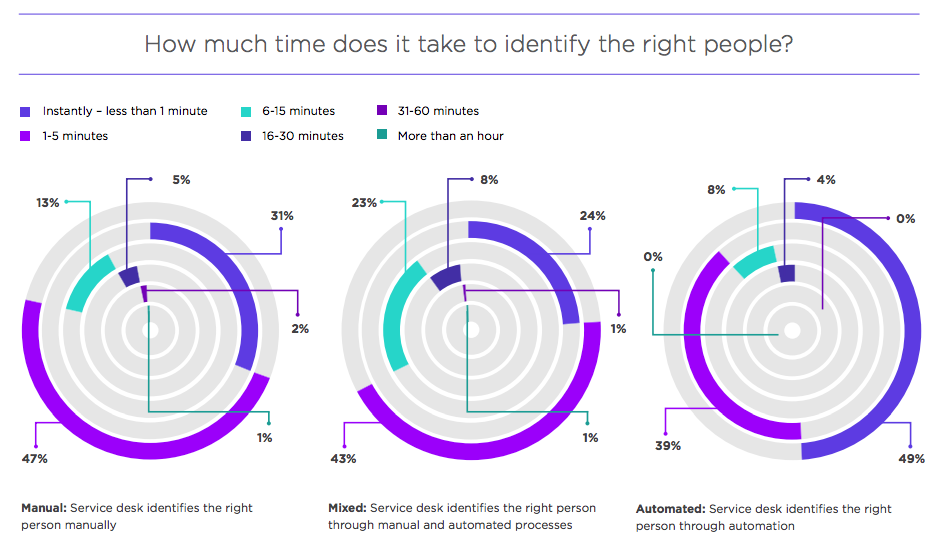
Time to identify by automation
You can learn more from the latest report from our survey on major incident management automation. It focuses on the effect of automation and integrations on incident management.
To learn more for yourself, take xMatters out for a spin.